Move over AlphaGo: AlphaZero taught itself to play three different games
Por um escritor misterioso
Last updated 16 junho 2024
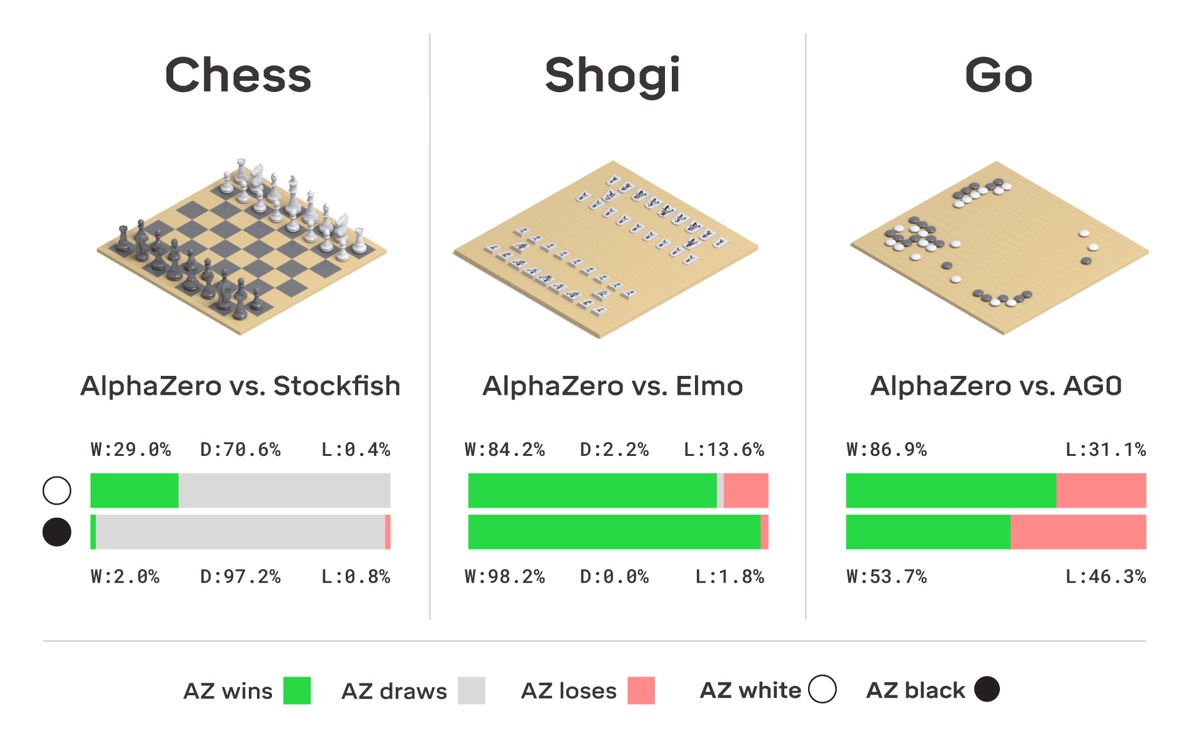
DeepMind's new AI is worthy successor to the first program to beat a human at Go.
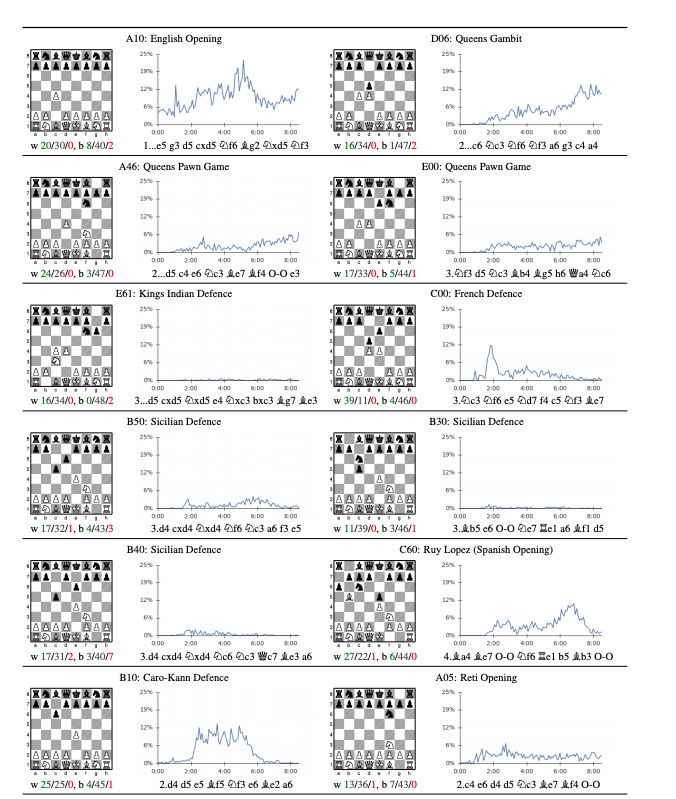
Towards Explainable AI for Chess - by Nate Solon

Understanding AlphaZero Neural Network's SuperHuman Chess Ability - MarkTechPost
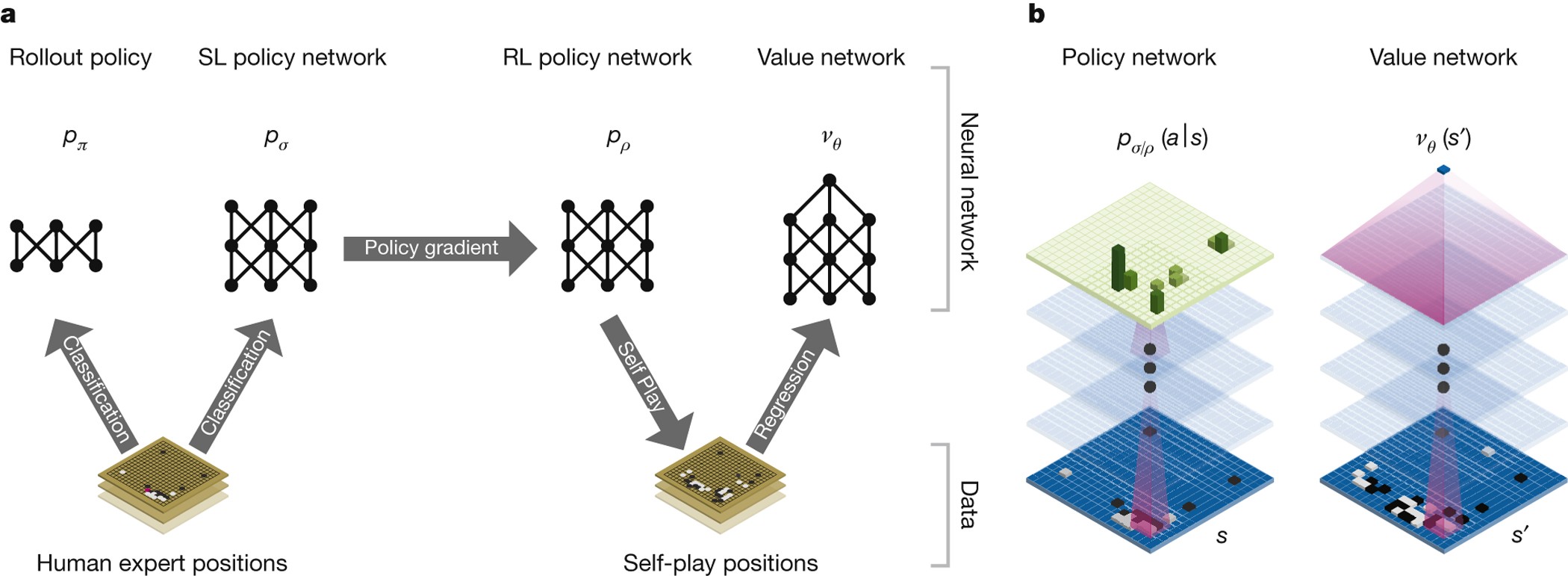
Mastering the game of Go with deep neural networks and tree search

Chess's New Best Player Is A Fearless, Swashbuckling Algorithm

New AlphaGo Zero Unsupervised AI is 100X Better While Using 10% Computing Power

The future is here – AlphaZero learns chess

AlphaZero AI beats champion chess program after teaching itself in four hours, DeepMind

AlphaZero Chess: How It Works, What Sets It Apart, and What It Can Tell Us, by Maxim Khovanskiy

Reinforcement learning explained

Simple Alpha Zero

AlphaGo taught itself how to win, but without humans it would have run out of time, Google
Recomendado para você
-
 AlphaZero - Wikipedia16 junho 2024
AlphaZero - Wikipedia16 junho 2024 -
 Left: Training AlphaZero by self-play gives artificial intelligence in16 junho 2024
Left: Training AlphaZero by self-play gives artificial intelligence in16 junho 2024 -
DeepMind's AlphaZero crushes chess16 junho 2024
-
 AlphaZero on Carlsen-Caruana Games 9-1216 junho 2024
AlphaZero on Carlsen-Caruana Games 9-1216 junho 2024 -
 Alphazero16 junho 2024
Alphazero16 junho 2024 -
 Google's AI teaches itself chess in 4 hours, then convincingly defeats Stockfish16 junho 2024
Google's AI teaches itself chess in 4 hours, then convincingly defeats Stockfish16 junho 2024 -
Chess Game Analysis, Chats and Sparring!, Chess Game Analysis, Chats and Sparring!, By Kamatyas16 junho 2024
-
 The Word is Compensation AlphaZero vs Stockfish16 junho 2024
The Word is Compensation AlphaZero vs Stockfish16 junho 2024 -
Alphazero Chess Games Pgn Download - Colaboratory16 junho 2024
-
 GitHub - Zeta36/chess-alpha-zero: Chess reinforcement learning by AlphaGo Zero methods.16 junho 2024
GitHub - Zeta36/chess-alpha-zero: Chess reinforcement learning by AlphaGo Zero methods.16 junho 2024



você pode gostar
-
 Moto X3M Winter: An absolutely thrilling ice racing game — Steemit16 junho 2024
Moto X3M Winter: An absolutely thrilling ice racing game — Steemit16 junho 2024 -
 Geography & Planography - Iconographic Encyclopædia of Science, Literature, and Art16 junho 2024
Geography & Planography - Iconographic Encyclopædia of Science, Literature, and Art16 junho 2024 -
 Investors feud over lead plaintiff status in Kohl's securities lawsuit - Milwaukee Business Journal16 junho 2024
Investors feud over lead plaintiff status in Kohl's securities lawsuit - Milwaukee Business Journal16 junho 2024 -
 Perfect World International Rising Tide, perfect world, forest, games, fantasy, HD wallpaper16 junho 2024
Perfect World International Rising Tide, perfect world, forest, games, fantasy, HD wallpaper16 junho 2024 -
 The Devil Is a Part-Timer!: Season 1 Blu-ray (Classics / はたらく魔王さま! / Hataraku Maou-sama!)16 junho 2024
The Devil Is a Part-Timer!: Season 1 Blu-ray (Classics / はたらく魔王さま! / Hataraku Maou-sama!)16 junho 2024 -
 You-rock GIFs - Get the best GIF on GIPHY16 junho 2024
You-rock GIFs - Get the best GIF on GIPHY16 junho 2024 -
 Caderno Pandalu By Luluca Médio- Caderno Inteligente em Promoção16 junho 2024
Caderno Pandalu By Luluca Médio- Caderno Inteligente em Promoção16 junho 2024 -
 Triângulo preto para jogo de bolas em plástico - BILHAR EL CONDOR16 junho 2024
Triângulo preto para jogo de bolas em plástico - BILHAR EL CONDOR16 junho 2024 -
 Bunzo Bunny - Best Price in Singapore - Oct 202316 junho 2024
Bunzo Bunny - Best Price in Singapore - Oct 202316 junho 2024 -
 All Of Us Are Dead Season 2 News & Updates: Everything We Know16 junho 2024
All Of Us Are Dead Season 2 News & Updates: Everything We Know16 junho 2024